移动端开发稳了?AI 目前还无法取代客户端开发,小红书的论文告诉你数据
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
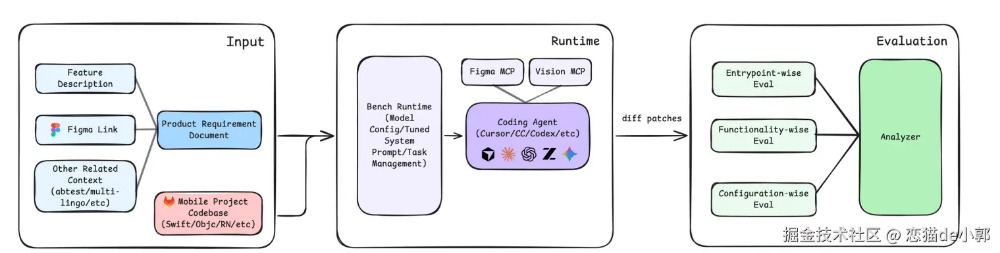
近期,由小红书联合多伦多大学等高校的研究人员发布了 《SWE-Bench Mobile》(2602.09540) 论文,内容主要是评估 LLM 智能体在处理真实生产级移动端应用开发任务时的能力,并提出了首个针对该领域的基准测试——SWE-Bench Mobile。 这个论文对比之前那些简单的需求场景,明显更具备说服力,最重要的是,用真实的数据给目前的 AI 狂热浇一浇冷水。
整个基准的规则是:
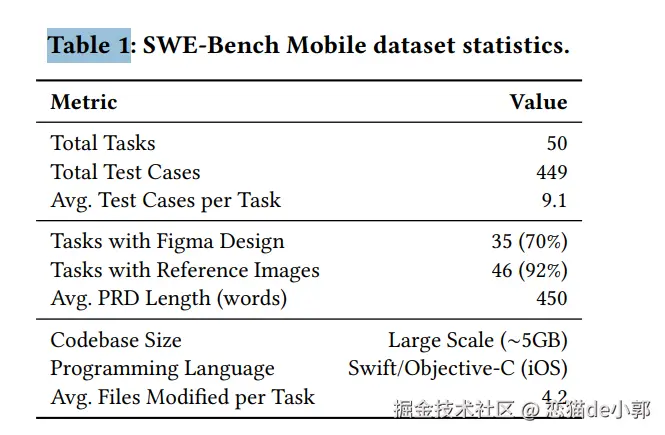
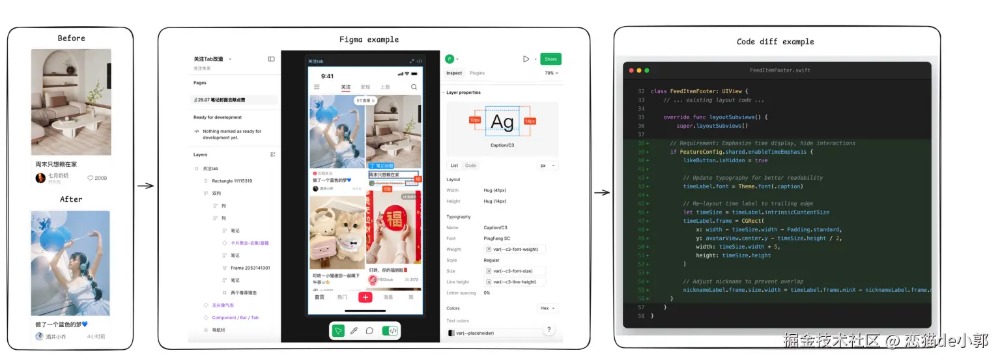
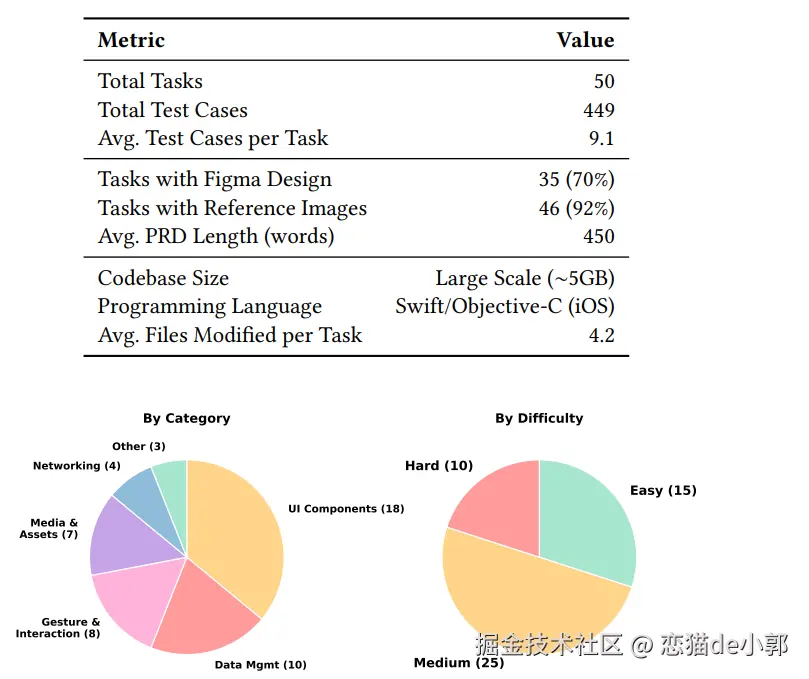
每个任务包含:
对于任务两个关键指标:
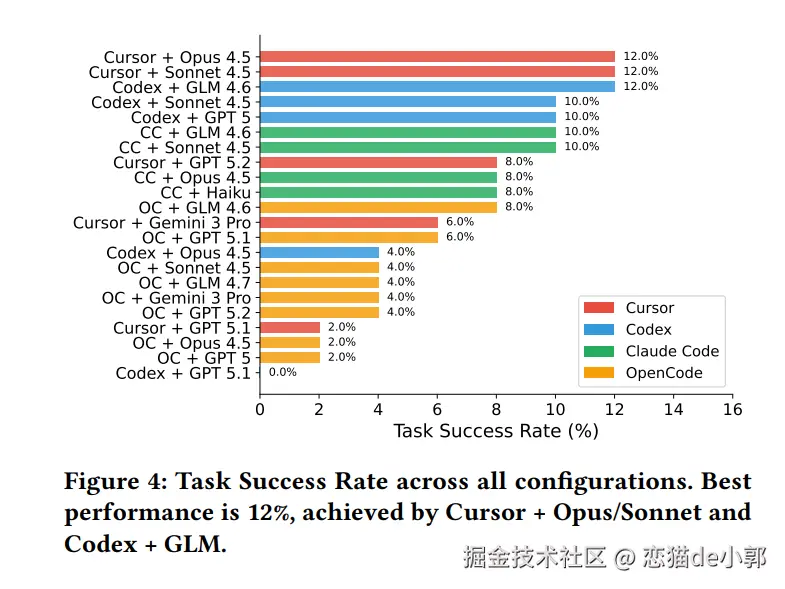
而对于 LLM,论文评估了 22 种 不同的“智能体-模型”配置,涵盖了四个主流框架:
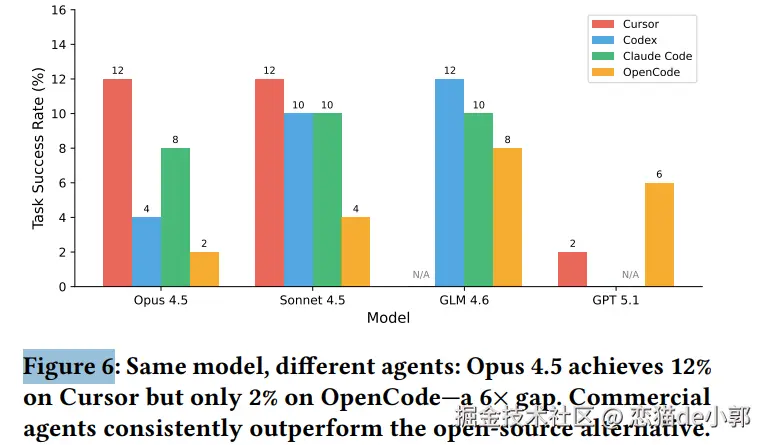
而根据论文可以得出结论:当前 AI 在生产级的软件工程力存在巨大局限性:
对于失败,论文还针对失败类型归类:
这些失败的类似,在一定程度上反映了智能体对真实工程流程、跨文件依赖、与视觉设计的理解严重不足,也就是这些问题是“工程级问题”,而不是“语言问题”:
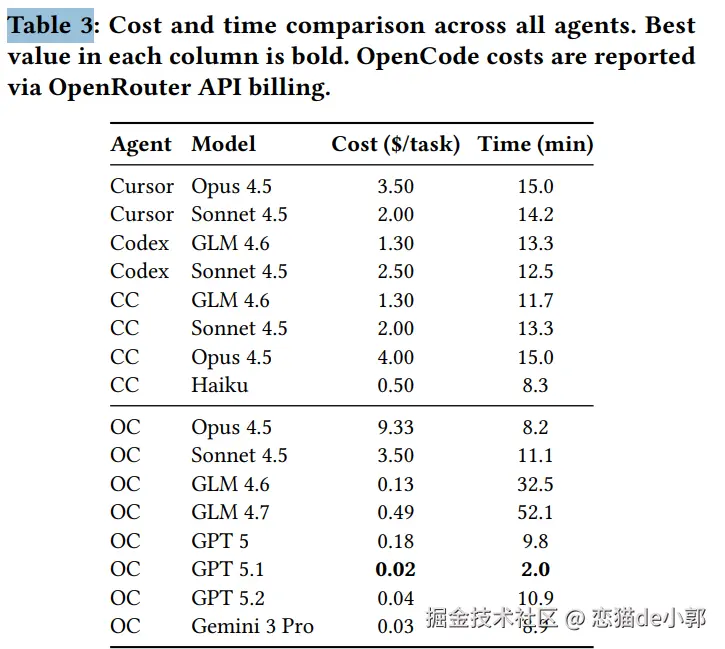
基于这些数据,论文认为当前 LLM Agent 尽管在单一代码生成上有突破,但在端到端工程上下文(包含设计、代码库理解、工程流程)仍远未达到企业生产标准。 另外,论文也有一个有趣的结论数据,主要统计了各 Agent + Model 的每任务成本(美元)和平均耗时(分钟),例如:
对此可以看出来:
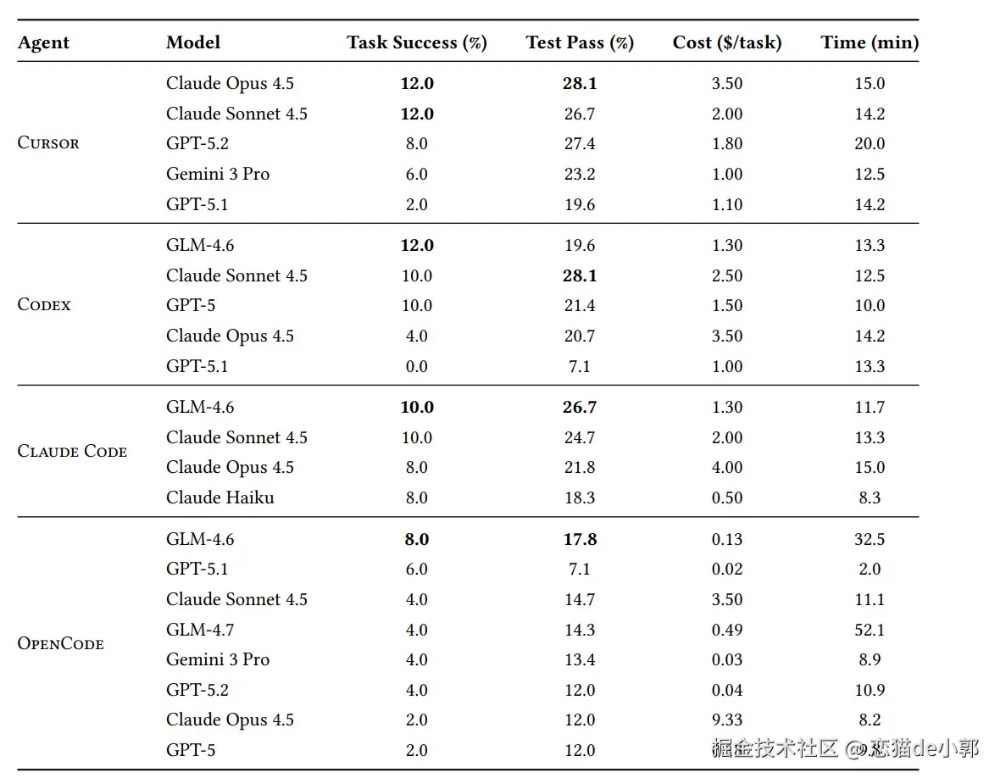
最后,下图是论文的最终结果对比,例如在 Success 和 Pass 上:
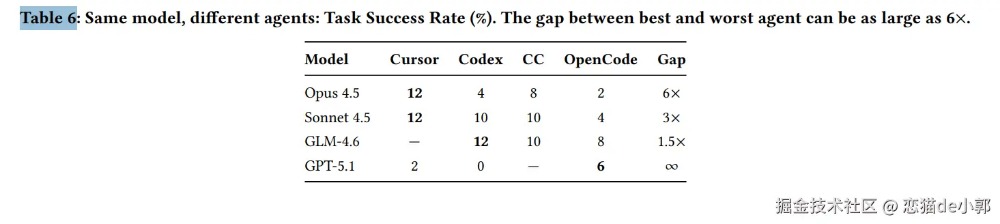 所以,可以看出来,目前的 AI 智能体离独立完成中大型移动开发还有很大距离,主要瓶颈在于多模态理解、大规模代码导航和跨文件逻辑一致性等。 另外,SWE-Bench Mobile 采用了托管基准挑战(Hosted Benchmark)模式 ,不公开测试集答案,以防止数据泄露到未来的模型训练中。 最后,论文只针对原生 iOS 开发进行测试,没有测试 Android 原生、Flutter、RN 等其他情况,按照一般直觉,这些框架的 AI 表现应该会好于 iOS 原生,当然这也只是我的个人直觉,真实数据还是得有企业做过 Benchmark 才知道。 不过至少从目前看,在移动端开发领域写代码上,至少比前端安全性高一些?你怎么看? 参考文章:原文链接 该文章在 2026/3/4 15:27:11 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886