C#.Net筑基-集合知识全解
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
01、集合基础知识.Net 中提供了一系列的管理对象集合的类型,数组、可变列表、字典等。从类型安全上集合分为两类,泛型集合 和 非泛型集合,传统的非泛型集合存储为Object,需要类型转。而泛型集合提供了更好的性能、编译时类型安全,推荐使用。 .Net中集合主要集中在下面几个命名空间中:
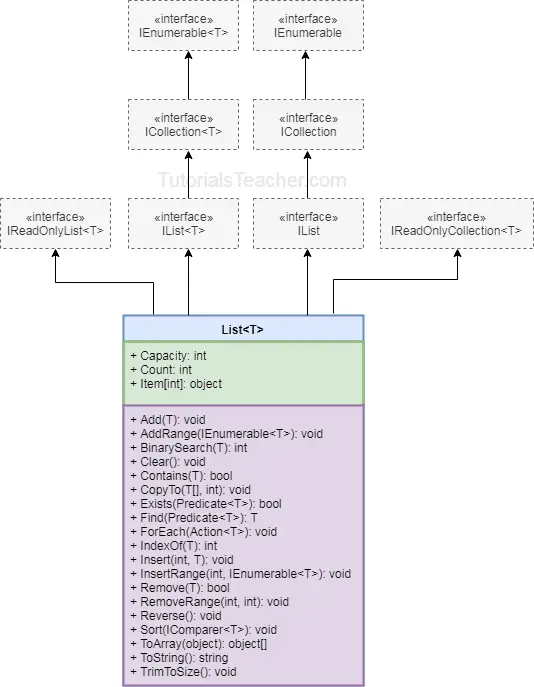
1.1、集合的起源:接口关系
1.2、非泛型集合—— 还有什么存在的价值?
❓既然非泛型版本类型不安全,性能还差,为什么还存在呢? 主要是历史原因,泛型是 1.3、 |
| public class Collection<T> | |
| { | |
| public Collection() | |
| { | |
| items = new List<T>(); | |
| } | |
| protected virtual void InsertItem(int index, T item) | |
| { | |
| items.Insert(index, item); | |
| } | |
| } |
foreach 用来循环迭代可枚举对象,用一种非常简洁、优雅的姿势访问可枚举元素。常用于数组、集合,当然不仅限于集合,只要符合要求枚举要求的都可以。
| foreach 可枚举类型 | 说明 |
|---|---|
| 数组 | 包括Array数组、List、字典等,他们都实现了IEnumerable接口的。 |
| IEnumerable | 可枚举接口 |
IEnumerable<T> | 同上,泛型版本 |
| GetEnumerator()方法 | 包含公共方法“IEnumerator GetEnumerator();”的任意类型 |
| yield迭代器 | yield语句实现的迭代器,实际返回的也是IEnumerable、IEnumerator |


枚举可以foreach 枚举的密码是他们都继承自IEnumerable接口,而更重要的是其内部的枚举器 —— IEnumerator。枚举器IEnumerator定义了向前遍历集合元素的基本协议,其申明如下:
public interface IEnumerator
{
object Current { get; }
bool MoveNext();
void Reset(); //这个方法是非必须的,用于重置游标,可不实现
}
public interface IEnumerator<out T> : IDisposable, IEnumerator
{
new T Current { get; }
}
MoveNext() 移动当前元素到下一个位置,Current获取当前元素,如果没有元素了,则MoveNext()返回false。注意MoveNext()会先调用,因此首次MoveNext()是把位置移动到第一个位置。
Reset()用于重置到起点,主要用于COM互操作,使用很少,可不用实现(直接抛出 NotSupportedException)。
📢 该接口不是必须的,只要实现了公共的
Current、无参MoveNext()成员就可进行枚举操作。
实现一个获取偶数的枚举器:
void Main()
{
var evenor = new EvenNumbersEnumerator(1, 10);
while (evenor.MoveNext())
{
Console.WriteLine(evenor.Current); //2 4 6 8 10
}
}
//获取偶数的枚举器
public struct EvenNumbersEnumerator : IEnumerator<int> //不继承IEnumerator接口,效果也是一样的
{
private int _start;
private int _end;
private int _position = int.MinValue;
public EvenNumbersEnumerator(int start, int end)
{
_start = start;
_end = end;
}
public int Current => _position;
object IEnumerator.Current => Current; //显示实现非泛型接口,然后隐藏起来
public bool MoveNext()
{
if (_position == int.MinValue)
_position = (int.IsEvenInteger(_start) ? _start : _start + 1) - 2;
_position += 2;
return (_position <= _end);
}
public void Reset() => throw new NotSupportedException();
public void Dispose() { } //IEnumerator 是实现了 IDisposable接口的
}
IEnumerable、IEnumerable<T>是所有集合的基础接口,其核心方法就是 GetEnumerator() 获取一个枚举器。
public interface IEnumerable
{
IEnumerator GetEnumerator();
}
public interface IEnumerable<out T> : IEnumerable
{
new IEnumerator<T> GetEnumerator();
}
📢 该接口也不是必须的,只要包含
public的“GetEnumerator()”方法也是一样的。
有了 GetEnumerator(),就可以使用foreach来枚举元素了,这里foreach会被编译为 while (evenor.MoveNext()){} 形式的代码。在上面 偶数枚举器的基础上实现 一个偶数类型。
void Main()
{
var evenNumber = new EvenNumbers();
foreach (var n in evenNumber)
{
Console.WriteLine(n); //2 4 6 8 10
}
}
public class EvenNumbers : IEnumerable<int> //不用必须继承接口,只要有GetEnumerator()即可
{
public IEnumerator<int> GetEnumerator()
{
return new EvenNumbersEnumerator(1, 10);
}
IEnumerator IEnumerable.GetEnumerator() //显示实现非泛型接口,然后隐藏起来
{
return GetEnumerator();
}
}
foreach 迭代其实就是调用其GetEnumerator()、Current、MoveNext()实现的,因此接口并不是必须的,只要有对应的成员即可。
foreach (var n in evenNumber)
{
Console.WriteLine(n); //2 4 6 8 10
}
/************** 上面代码编译后的效果如下:*****************/
IEnumerator<int> enumerator = evenNumber.GetEnumerator();
try
{
while (enumerator.MoveNext ())
{
int i = enumerator.Current;
Console.WriteLine (i);
}
}
finally
{
if (enumerator != null)
{
enumerator.Dispose ();
}
}
yield return 是一个用于实现迭代器的专用语句,它允许你一次返回一个元素,而不是一次性返回整个集合。常来用来实现自定义的简单迭代器,非常方便,无需实现IEnumerator接口。
🔸惰性执行:元素是按需生成的,这可以提高性能并减少内存占用(当然这个要看具体情况),特别是在处理大型集合或复杂的计算时。迭代器方法在被调用时,不会立即执行,而是在MoveNext()时,才会执行对应yield return的语句,并返回该语句的结果。📢Linq里的很多操作也是惰性的。
🔸简化代码:使用yield return可以避免手动编写迭代器的繁琐过程。
🔸状态保持:yield return自动处理状态保持,使得在每次迭代中保存当前状态变得非常简单。每一条yield return语句执行完后,代码的控制权会交还给调用者,由调用者控制继续。

yield迭代器方法会被会被编译为一个实现了IEnumerator 接口的私有类,可以看做是一个高级的语法糖,有一些限制(要求):
迭代器的返回类型可以是IEnumerable、IEnumerator或他们的泛型版本。还可以用 IAsyncEnumerable<T> 来实现异步的迭代器。
yield break 语句提前退出迭代器,不可直接用return,是非法的。
yield语句不能和try...catch一起使用。
void Main()
{
var us = new User();
foreach (string name in us)
{
Console.WriteLine(name); //sam kwong
}
foreach (string name in us.GetEnumerator1())
{
Console.WriteLine(name); //1 sam 2
}
foreach (string name in us.GetEnumerator2())
{
Console.WriteLine(name);//KWONG
}
}
public class User
{
private string firstName = "sam";
private string lastName = "Kwong";
public IEnumerator GetEnumerator()
{
yield return firstName;
yield return lastName;
}
public IEnumerable GetEnumerator1() //返回IEnumerable
{
Console.WriteLine("1");
yield return firstName; //第一次执行到这里
Console.WriteLine("2");
yield break; //第二次执行到这里,也是最后一次了
yield return lastName;
}
public IEnumerable<string> GetEnumerator2() //返回IEnumerable<string>
{
yield return lastName.ToUpper();
}
}

| 集合类型 | 特点/说明 |
|---|---|
| Array(数组之父) | 是一个抽象类,是有所有数组的父类,提供了很多用于数组操作的静态方法,详见下一章节 |
数组:T[]⭐ | 定长(内存连续)的数组集合,所有数组都继承自 Array,int[] arr = {1,2,3}; |
| ArrayList | 可变长数组,存放Object对象,内部会自动扩容,很少使用。 |
List<T>⭐ | 泛型版的ArrayList,可变长集合,很常用。 |
| HashTable | 存储Key、Value结构的哈希表,可根据Key快速获取Value值。Key不可重复,都是Object类型。 |
Dictionary<TK, TV>⭐ | 泛型版本的哈希表,代替HashTable |
HashSet<T> | 只有Key的Dictionary,Key不可重复,适用于与不可重复的集合 |
SortedSet<T> | 支持排序的HashSet,内部用一个红黑树存储,添加删除慢,因为要维护元素的状态 |
Queue、Queue<T> | 队列,先进先出(FIFO),Enqueue(后入)、Dequeue(前出) |
PriorityQueue<T, TP> | 支持优先级顺序的队列,只能保证优先级顺序,相同优先级不保证先进先出 |
Stack、Stack<T> | 栈表,后进先出(LIFO),Push(前入)、Pop(前出) |
SortedList<TKey,TValue> | 按照Key排序的列表,内部为数组,支持索引器,在插入时按照顺序存储(性能较差) |
SortedDictionary<TK,TV> | 同SortedList,内部为红黑树存储键值对,大数据量时性能更好,不支持索引器。 |
LinkedList<T> | 双向链表,每个节点包含一个值、前节点指针、后节点指针,不支持索引器。插入删除很快O(1),不会移动元素,查找O(n)较慢,会遍历整个集合。 |
| ListDictionary | 单向链表字典,轻量级的字典,它适用于小型集合(小于10个)。 |
| HybridDictionary | Hashtable(高查询效率)和ListDictionary(内存少)的杂交集合,根据数量内部切换容器。 |
ReadOnlyCollection<T> | 只读集合,接收一个IList集合,可以看做是对普通集合的只读包装,修改会抛出异常。 |
| Immutable*** | 不可变集合,通过静态方法Create()创建并初始化,任何修改都会创建新的集合。 |
Collection<TItem> | 专为自定义扩展(继承)用的集合基类 |
KeyedCollection<TK, TV> | 同上,专为自定义扩展(继承)用的字典集合基类,继承自Collection<TItem> |
| BitArray | 位数组(不是字节,只有一位),用来存储bool值,支持位操作。 |
| Concurrent*** | 线程安全的集合,各种类型的集合都有线程安全的版本,可多线程访问 |
ConcurrentQueue<T> | 线程安全的队列 Queue |
ConcurrentStack<T> | 线程安全的栈表 Stack |
ConcurrentDictionary<T,K> | 线程安全的字典 Dictionary |
BlockingCollection<T> | 提供阻塞功能的线程安全集合,适合用于生产者-消费者场景,消费者会自动阻塞等待生产者消息 |
ConcurrentBag<T> | 线程安全的集合List<T> |
Channel<T> | 专用于生产、消费场景的现代异步消息队列,比 BlockingCollection更强大、灵活。 |
ArrayList arr2 = new ArrayList();
arr2.Add(null);
arr2.Add("sam");
arr2.Add(1);
Console.WriteLine(arr2[1]);
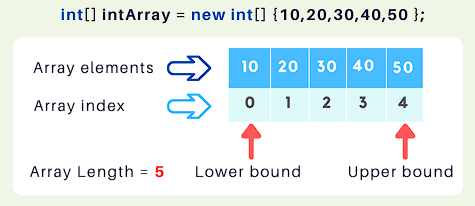
Array 数组是一种有序的集合,通过唯一索引编号进行访问。数组T[]是最常用的数据集合了,几乎支持创建任意类型的数组。Array是所有的数组T[]的(隐式)基类,包括一维、多维数组。CLR会将数组隐式转换为 Array 的子类,生成一个伪类型。
索引从0开始。
定长:数组在申明时必须指定长度,超出长度访问会抛出IndexOutOfRangeException异常。
内存连续:为了高效访问,数组元素在内存中总是连续存储的。如果是值类型数组,值和数组是存储在一起的;如果是引用类型数组,则数组值存储其引用对象的(堆内存)地址。因此数组的访问是非常高效的!
多维数组:矩阵数组 用逗号隔开,int[,] arr = {{1,2},{3,4}};
多维数组:锯齿形数组(数组的数组),int[][] arr =new int[3][];
int[] arr = new int[100]; //申请长度100的int数组
int[] arr2 = new int[]{1,2,3}; //申请并赋值,长度为3
int[] arr3 = {1,2,3}; //同上,前面已制定类型,后面可省略
arr[1] = 1;
Console.WriteLine(arr[2]); //未赋值,默认为0
📢 几乎大部分编程语言的数组索引都是从0开始的,如C、Java、Python、JavaScript等。当然也有从1开始的,如MATLAB、R、Lua。
| 属性 | 特点/说明 |
|---|---|
| Length | 数组的长度、元素的数量 |
| Rank | 获取数组的维度,一维数组就是1 |
| [int index] | 索引器,这是方法数组元素的最常用方式,没有之一! |
| 🔸方法 | 特点/说明 |
AsReadOnly<T>(T[]) | 获取一个只读的数组 ReadOnlyCollection<T> |
| CopyTo(array, index) | 复制数组元素到目标数组array,参数index为目标array的索引位置 |
| object? GetValue(Int32) | 获取制定索引位置的值,对应的还有SetValue(obj, index),这两个方法都会装箱,慎用! |
| 🔸静态方法 | 特点/说明 |
| BinarySearch(Array) | 二分查找,返回找到的元素的索引,负数表示没找到。前提是数组必须是有序的。 |
| Clear(Array) | 清除数组的内容 |
| Clone() | 创建 Array 的浅表副本 |
| Copy(array1, array2) | 将一个array1中的元素复制到数组array2中 |
| CreateInstance(Type, len) | 创建数组,指定类型和长度,Array.CreateInstance(typeof(int),10) |
Exists<T>(arr, Predicate) | 根据谓词条件判断是否存在的元素,返回bool,Array.Exists(arr,s=>s>5) |
| Array.Fill(arr, value) | 填充数组值为value,Array.Fill(arr,1); |
Find<T>(arr, Predicate) | 根据条件查找元素,返回第一个匹配的元素,Array.Find(arr,s=>s>5) |
| FindLast(arr, Predicate) | 同上,返回最后一个匹配的元素 |
| FindAll(arr, Predicate) | 查找所有匹配的元素,返回数组。 |
| FindIndex(T[], Predicate) | 查找第一个匹配元素的索引,对应的还有 FindLastIndex |
ForEach(T[], Action<T>) | 循环遍历元素执行action |
| IndexOf、LastIndexOf | 根据元素查找索引位置,-1表示没找到 |
Reverse<T>(T[]) | 反转元素顺序,Array.Reverse(arr),不会创建新数组。‼️Linq的Reverse会创建新对象 |
Resize<T>(ref T[], Int) | 更改数组长度,会创建一个新数组,所以用了ref |
| Sort(Array) | 对数组元素排序,Array.Sort(arr),不会创建新数组。 |
| TrueForAll(T[], Predicate) | 判断是否所有元素都符合维词条件,返回bool,Array.TrueForAll(arr,s=>s>1) |
| 🔸扩展方法 | 特点/说明 |
IEnumerable Cast<T>() | 强制转换为指定类型的数组,延迟实现+会装箱,var arr2 = arr.Cast<uint>() |
| AsSpan() | 创建数组的Span<T>对象 |
| AsMemory() | 创建数组的Memory<T>对象 |
📢 通过上表发现,Array 的很多方法都是静态方法,而不是实例方法,这一点有点困惑,造成了使用不便。而且大部分方法都可以用Linq的扩展来代替。
LINQ to Objects (C#) 提供了大量的对集合操作的扩展,可以使用 LINQ 来查询任何可枚举的集合(IEnumerable)。扩展实现主要集中在 代码 Enumerable 类(源码 Enumerable.cs),涵盖了查询、排序、分组、统计等各种功能,非常强大。
简洁、易读,可以链式操作,简单的代码即可实现丰富的筛选、排序和分组功能。
延迟执行,只有在ToList、ToArray时才会正式执行,和yeild一样的效果。
var arr = Enumerable.Range(1, 100).ToArray(); //生成一个数组
var evens = arr.Where(n => int.IsEvenInteger(n)); //并没有执行
var arr2 = arr.GroupBy(n => n % 10).ToArray();
| 技巧 | 说明 |
|---|---|
| 集合初始化器{} | 省略new和类型,用{}初始化值,int[] arr = {1,2,3}; |
| 集合表达式[] | C#12,简化集合赋值,比上面更简化,int[] arr = [1,2,3] |
范围运算符 a..b | C#8,表示a到b的范围(不含b),可获取集合中指定范围的子集var sub =arr[1..3] |
^n倒数 | C#8,索引倒数,arr[^1]//倒数第一个 |
| ..展开运算符 | 支持集合、可枚举表达式,展开每个枚举元素到数组,配合集合表达式使用比较方便。 |

同类的初始化器类似,用{}来初始化设置集合值,支持数组、字典。
//数组
int[] arr1 = new int[3] { 1, 2, 3 };
int[] arr2 = new int[] { 1, 2, 3 };
int[] arr4 = { 1, 2, 3 };
//字典
Dictionary<int, string> dict1 = new() { { 1, "sam" }, { 2, "william" } };
Dictionary<int, string> dict2 = new() { [5] = "sam", [6] = "zhangsan" }; //索引器写法
var dict3 = new Dictionary<int, string> { { 1, "sam" }, { 2, "william" } };
集合表达式 简化了集合的申明和赋值,直接用[]赋值,比初始化器更简洁,语法形式和JavaScript差不多了。可用于数组、Sapn、List,还可以自定义集合生成器。
int[] iarr1 = new int[] { 1, 2, 3, 4 }; //完整的申明方式
int[] iarr2 = { 1, 2, 3, 4 }; //前面声明有类型int[],可省略new
int[] iarr3 = [1, 2, 3, 4]; //简化版的集合表达式
List<string> list = ["a1", "b1", "c1"];
Span<char> sc = ['a', 'b', 'c'];
HashSet<string> set = ["a2", "b2", "c2"];
//..展开运算符,把集合中的元素展开
List<string> list2 = [.. list,..set, "ccc"]; //a1 b1 c1 a2 b2 c2 ccc
a..b表示a到b的范围(不含b),其本质是 System.Range 类型数据,表示一个索引范围,常用与集合操作。
可省略a或b,缺省则表示到边界。
可结合倒数^使用。
int[] arr = new[] { 0, 1, 2, 3, 4, 5 };
Console.WriteLine(arr[1..3]); //1 2 //索引1、2
Console.WriteLine(arr[3..]); //3 4 5 //索引3到结尾
Console.WriteLine(arr[..]); //全部
Console.WriteLine(arr[^2..]); //4 5 //倒数到2到结尾
var r = 1..3;
Console.WriteLine(r.GetType()); //System.Range
自定义的索引器也可用用范围
Range作为范围参数。
| 技巧 | 说明 |
|---|---|
| 使用泛型版本集合 | 尽量不使用非泛型版本的集合(如ArrayList、Hashtable),避免装箱。 |
| 初始化合适的容量 | 创建集合时,根据实际情况尽量给定一个合适的初始容量,避免频繁的扩容 |
| 使用Span | 使用Span<T>和Memory<T>进行高效内存访问,更多参考《高性能的Span、Memory》 |
使用ArrayPool<T> | 对于频繁获取集合数据的场景,采用池化技术复用数组对象,减少数组对象的创建 |
🚩尽量给集合一个合适的“容量”( capacity),几乎所有可变长集合的“动态变长”其实都是有代价的。他们内部会有一个定长的“数组”,当添加元素较多(大于容量)时,就会自动扩容(如倍增),然后把原有“数组”数据拷贝(搬运)到新“数组“中。
因此在使用可变长集合时,尽量给一个合适的大小,可减少频繁扩容带来的性能影响。当然也不可盲目设置一个比较大的容量,这就很浪费内存空间了。stringBuilder也是一样的道理。
可变长集合的插入、删除效率都不高,因为会移动其后续元素。
下面测试一下List<T>,当创建一个长度为1000的List时,设置容量(1000)和不设置容量(默认4)的对比。
int max = 10000;
public void List_AutoLength(){
List<int> arr = new List<int>();
for (int i = 0; i < max; i++)
{
arr.Add(i);
}
}
public void List_FixedLength()
{
List<int> arr = new List<int>(max);
for (int i = 0; i < max; i++)
{
arr.Add(i);
}
}

很明显,自动长度的List速度更慢,也消耗了更多的内存。

🚩尽量不创建新数组,使用一些数组方法时需要注意尽量不要创建新的数组,如下面示例代码:
var arr = Enumerable.Range(1, 100).ToArray();
// 需求:对arr进行反序操作
var arr2 = arr.Reverse().ToArray(); //用Linq,创建了新数组
Array.Reverse(arr); //使用Array的静态方法,原地反序,没有创建新对象
比较一下上面两种反序的性能:

转自https://www.cnblogs.com/anding/p/18229596






 400 186 1886
400 186 1886






